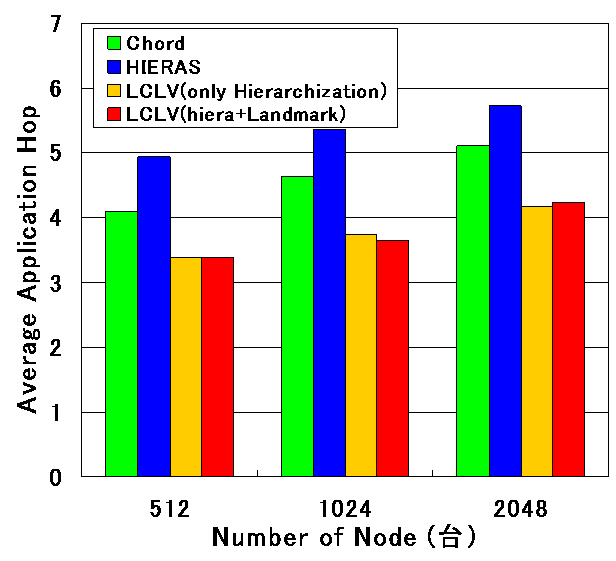
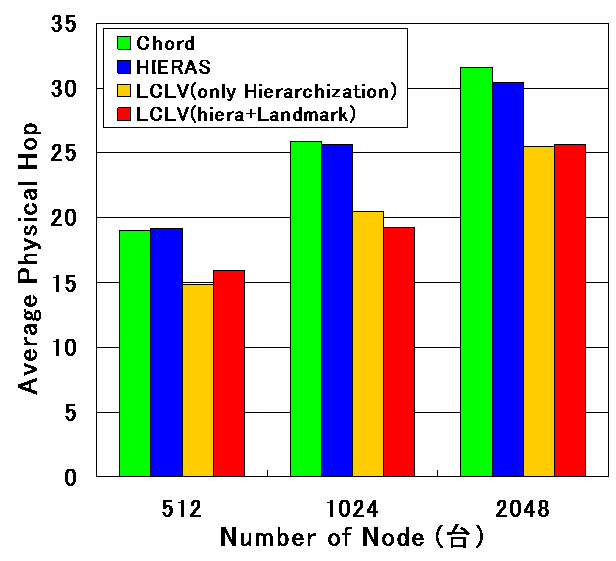
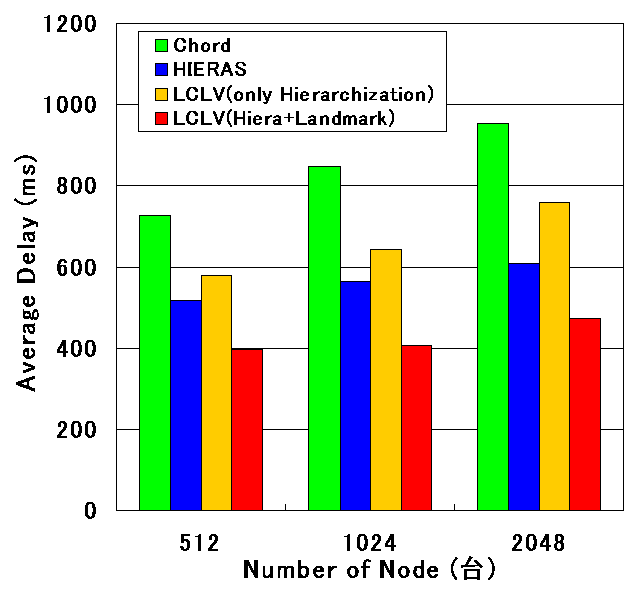
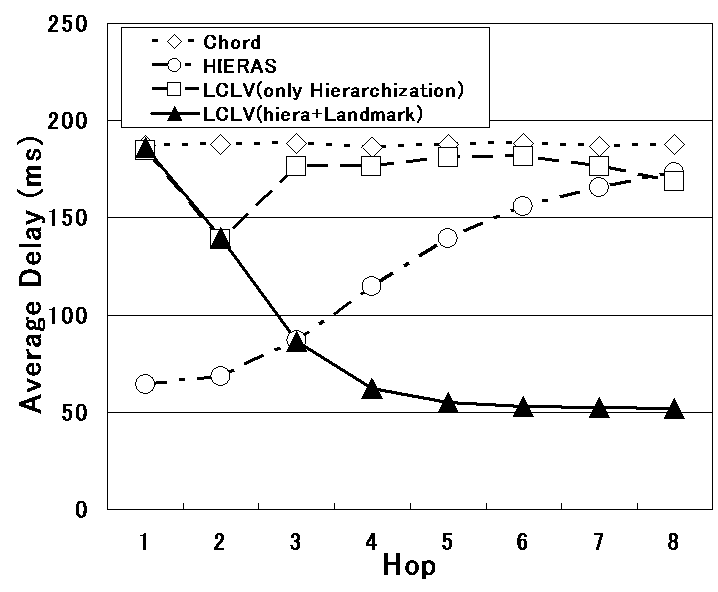
ランドマークベクトルによる ID の生成法
LCLV は物理ネットワーク上での距離を通信に必要な遅延時間により近似可能であ るという前提のもとに、遅延時間の短いノード同士は、分散ハッシュ上のネットワー クにおいても近くなるようなID を生成します。LCLV における新しいノード N の ID の生成の流れを以下に示します。
- 各ランドマークの2次元空間での位置(座標)を求める。
- 各ランドマークの座標と、 N から各ランドマークへの通信遅延時間 から、 N の2次元空間での座標を求める。
- 決定された座標から ID を生成。
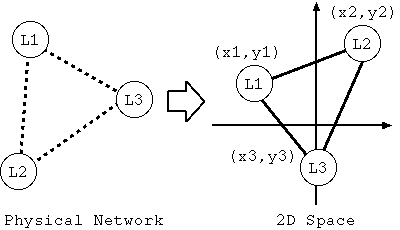
図1:ランドマークを用いた2次元空間へのマッピング
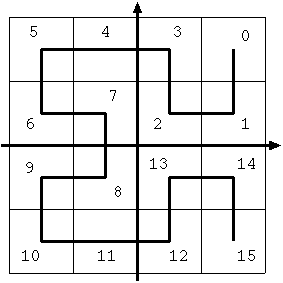
図2:Space Filling Curve を用いた ID の割り当て
まず,ランドマークノードを図1 のように2次元空間にマッピングします(1)。 その方法として、各ランドマーク間の物理ネットワーク上での通信遅延時 間を測定し、測定された遅延と2次元空間での距離との誤差の和が最小となる点に ランドマークを配置します。次に同様の方法を用いて、今 ID を決定したいノード N の2次元空間での座標を求めます(2)。以上の方法で、物理ネットワークで 近いノード同士は、2次元空間においても近似的に近い座標を得ることが可能となり ます。次に、2次元空間をいくつかの空間に分け、そこに図2 のように空間充填曲 線(Space Filling Curve : SFC)を引きます。ここでは、空間充填曲線として Hilbert 曲線を用いました。そして、空間充填曲線が通った順に数字を割り当て ます。このとき、ノード N が存在する座標上の空間充填曲線によって割り 当てられた数字をノードの ID として新たに割り当てます(3)。
この方法を用いることにより、物理ネットワークで近いノード同士を、分散ハッ シュ上での ID においてもおおよそ近い ID に割り当てることが可能となります。
階層化
LCLV における階層化は、 Chord で用いる ID を数ビット毎に区切ること で行います。例として、 ID の大きさが12ビット、階層数が2、 第一階層の ID が3ビット、第二階層の ID が9ビットとし、 あるノード N のID が8進数表示で ID = 7042 と与えられた場合を考えます。 この場合、第一階層の ID は 7 となり、 第二階層の ID は 042 となります。つまり、図3 のように階層を分 けることになり、ノード N は図中の位置に配置されます。 このような階層化において、それぞれの階層は ID が小さいため、 もとの Chord よりも小さい規模のネットワークとなります。 このように LCLV は,小さな規模のネットワークに分けること で階層化を行います。 HIERAS は各階層で Chord と同じ大きさのネットワークを生成するため、 LCLV の方が維持コスト、テーブル量において優位です。LCLV では上位の階層の ID のみを先ほど説明したランドマークベ クトルによる ID を使用し、最下層の ID は通常の Chord と同様にハッシュ関数 を使用して割り当てます。
このような ID の割り当て方式を用いることにより、図2 においては, 第一階層でのネットワークは物理的に遠いノード同士のネットワークとなるため、 この階層における通信遅延は大きくなります。 しかし、第二階層でのネットワークは物理的に近いノード同士で構成されるため、 通信遅延は小さくなります。
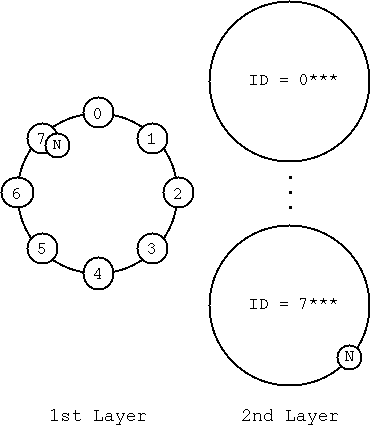
図3:LCLV における階層化されたネットワーク