- CPU:Pentium III 866MHz x 2
- Memory:512Mbyte
- OS:Solaris 8
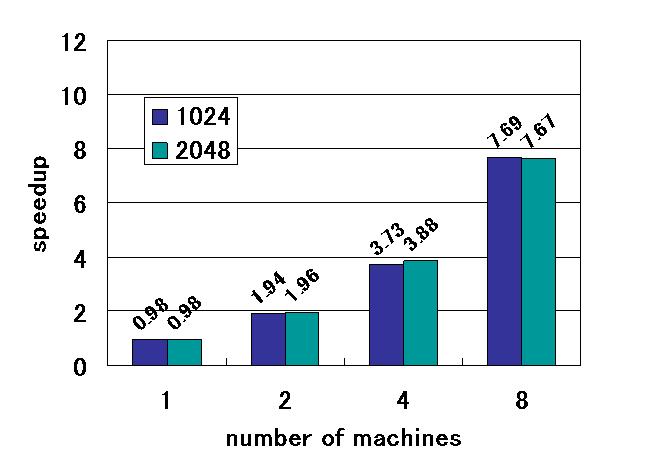
恾侾丗峴楍愊墘嶼偺懍搙岦忋棪丂
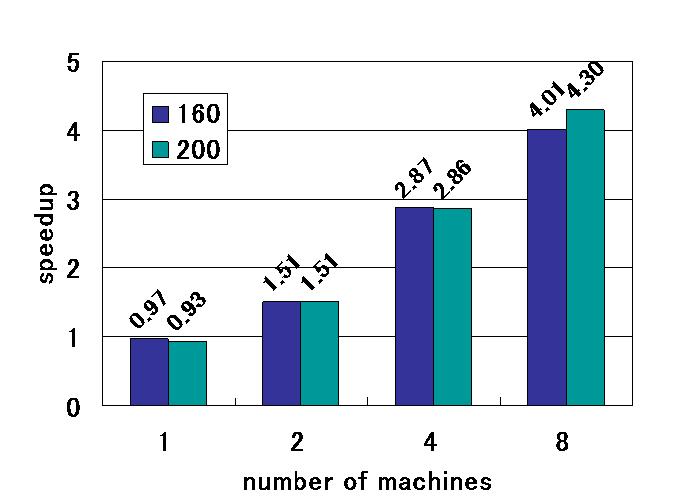
恾侾丗俥俢俿俢朄偵傛傞揹帴奅僔儈儏儗乕僔儑儞偺懍搙岦忋棪丂
僊僈儕儞僌僋儔僗僞忋偱偺忢帪揮憲宆暘嶶嫟桳儊儌儕僔僗僥儉
嵟廔峏怴丗2004/3/11
杮尋媶幒偱偼丆崅懍側捠怣懍搙傪傕偮僱僢僩儚 乕僋僇乕僪傪棙梡偟偨儕儞僌寢崌宆寁嶼婡僋儔僗僞(僊僈儕儞僌僋儔僗 僞)忋偱偺怴偟偄暘嶶嫟桳儊儌儕儌僨儖偺尋媶傪峴偭偰偄 傑偡丅
変乆偑採埬偡傞暘嶶嫟桳儊儌儕儌僨儖偱偼丆嫟桳儊儌儕嬻娫傪僊僈儕儞 僌僋儔僗僞撪偱忢帪揮憲忬懺偲偟傑偡丅 嫟桳儊儌儕嬻娫偑崅懍偵僊僈儕儞僌僋儔僗僞撪傪堏摦偟偮偯偗傞偙偲偱丆 偁偨偐傕奺寁嶼婡偑偡傋偰偺嫟桳曄悢傪曐帩偟偰偄傞偐偺傛偆偵嫟桳 曄悢傪巊梡偡傞偙偲偑壜擻偲側傝傑偡丅
採埬儌僨儖偱偼嫟桳儊儌儕嬻娫慡懱偺揮憲傪峴偆偨傔丆崅懍側僱僢僩 儚乕僋偑昁梫偲側傝傑偡丅 偦偺偨傔丆杮尋媶偱偼恾侾偵帵偡僊僈儕儞僌僋儔僗僞忋偵採埬儌僨儖 傪幚憰偟偰偄傑偡丅僊僈儕儞僌僋儔僗僞偲偼丆崅懍側捠怣懍搙傪帩偮 Giga Ethernet傪梡偄偰暋悢偺寁嶼婡傪儕儞僌忬偵愙懕偟偨寁嶼婡僋儔 僗僞偱偡丅 侾偮偺寁嶼婡偑俀偮偺Giga Ethernet僀儞僞乕僼僃乕僗傪巊梡偟丆偦傟 偧傟偺僀儞僞僼僃乕僗偑堎側傞寁嶼婡偲愙懕偝傟偰偄傑偡丅側偍丆捠怣 帪偺僐儕僕儑儞(徴撍)傪杊偖偨傔丆僗僀僢僠儞僌僴僽摍傪夘偝偢捈愙愙 懕偟偰偄傑偡丅 傑偨丆Giga Ethernet傪梡偄偨愙懕偲偼暿偵丆FastEthernet傪梡偄偨僱僢 僩儚乕僋愙懕傕曐帩偟丆嫟桳儊儌儕嬻娫偺傛偆側戝偒側僨乕僞揮憲偼Giga Ethernet傪棙梡偟丆惂屼怣崋側偳偺彫偝側僨乕僞偺揮憲偼Fast Ethernet 傪棙梡偟傑偡丅傑偨丆嫟桳曄悢偺捠怣晹偵偼丆寁嶼俠俹倀偵晧壸傪偐偗傞偙偲側偔崅懍側 揮憲偑壜擻側僴乕僪僂僃傾傾乕僉僥僋僠儍傪梡偄傞偙偲傪憐掕偟偰偄傑偡丅
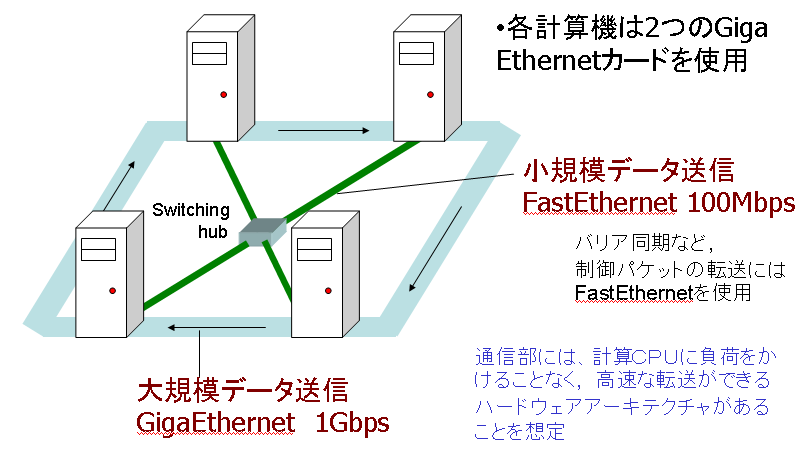
恾侾丗僊僈儕儞僌僋儔僗僞丂
僾儘僌儔儉偱昁梫偲側偭偨帪揰(僆儞僨儅儞僪)偱懠寁嶼婡偺帩偮儊儌儕椞堟傊偺 傾僋僙僗傪峴偆応崌丆捠怣偺弶婜抶墑偵傛傞僆乕僶乕僿僢僪偑栤戣偲側傝傑偡丅 偦偙偱丆捠怣偺弶婜抶墑偺栤戣傪夝徚偡傞偨傔偵丆変乆偺尋媶幒偱偼忢帪揮憲宆 暘嶶嫟桳儊儌儕傪採埬偟偰偄傑偡丅 忢帪揮憲宆暘嶶嫟桳儊儌儕偼丆廬棃偺傛偆偵僆儞僨儅儞僪偵懠寁嶼婡偺僨乕僞傪 梫媮偡傞偺偱偼側偔丆偲偄偆奣擮偵婎偯偔暘嶶嫟桳儊儌儕儌僨儖偱偡丅 偙偺儌僨儖偱偼丆懠寁嶼婡偵懳偟偰僆儞僨儅儞僪偵儊儌儕嶲徠梫媮傪峴傢側偄偨 傔丆捠怣偺弶婜抶墑偺栤戣傪庴偗傑偣傫丅傑偨丆嫟桳曄悢偺揮憲偲寁嶼偼撈棫 偵峴傢傟傞偨傔丆捠怣偲寁嶼傪僆乕僶乕儔僢僾偝偣傞偙偲偑梕堈偲偄偆摿挜偑 偁傝傑偡丅
- 崅懍側捠怣懍搙傪傕偮僱僢僩儚乕僋傪棙梡偟丆嫟桳儊儌儕嬻娫慡懱傪僋 儔僗僞撪偱忢帪揮憲忬懺偲偡傞丅
- 奺寁嶼婡偼丆偦偺帪崗偵曐帩偟偰偄傞嫟桳儊儌儕椞堟傪梡偄偰幚峴偡傞 偙偲偑壜擻側僞僗僋傪峴偆丅
- 昁梫側嫟桳曄悢傪摼傜傟偢丆嶲徠傑偨偼戙擖張棟傪幚峴偱偒側偄僞僗僋 偼丆堦帪僉儏乕偵奿擺偟丆幚峴壜擻帪傑偱張棟傪抶傜偣傞丅
採埬儌僨儖傪幚峴偡傞儔儞僞僀儉儔僀僽儔儕傪丆C++偺僋儔僗儔僀僽儔儕偲偟偰幚憰偟偰 惈擻昡壙傪峴偄傑偟偨丅 幚尡偵偼丆埲壓偺寁嶼婡傪梡偄偨僊僈儕儞僌僋儔僗僞娐嫬傪梡偄傑偟偨丅 側偍丆採埬庤朄偱偼嫟桳曄悢偺捠怣晹偵寁嶼CPU偵晧壸傪偐偗傞偙偲側偔丆 崅懍側揮憲偑偱偒傞僴乕僪僂僄傾傾乕僉僥僋僠儍傪憐掕偟偰偄傑偡偑丄 杮幚尡偱偼偦偺偐傢傝偵俀俠俹倀偺俽俵俹寁嶼婡傪梡偄丆侾俠俹倀傪捠怣愱梡 僾儘僙僢僒偲偟偰巊梡偟傑偟偨丅惈擻昡壙偵偼丆峴楍愊偺寁嶼偲FDTD朄傪梡偄偨揹帴奅僔儈儏儗乕僔儑儞傪梡 偄傑偟偨丅 偦傟偧傟偺寢壥傪恾俀丆恾俁偵帵偟傑偡丅墶幉偼巊梡寁嶼婡戜悢丆廲幉偼懍 搙岦忋棪偱偡丅懍搙岦忋棪偼丆乽C僾儘僌儔儉偱嶌惉偟偨拃師僾儘僌儔儉偱偺幚 峴帪娫 / 採埬庤朄偱偺幚峴帪娫乿偱偡丅偙偺寢壥丆峴楍愊墘嶼偱栺俈丏俈攞丆 俥俢俿俢朄偵傛傞揹帴奅僔儈儏儗乕僔儑儞偱栺係攞偺懍搙岦忋偑摼傜傟傞偙偲偑 妋擣偝傟傑偟偨丅
- CPU:Pentium III 866MHz x 2
- Memory:512Mbyte
- OS:Solaris 8
恾侾丗峴楍愊墘嶼偺懍搙岦忋棪丂
恾侾丗俥俢俿俢朄偵傛傞揹帴奅僔儈儏儗乕僔儑儞偺懍搙岦忋棪丂