マルチエージェント強化学習
マルチエージェント強化学習は、複数の強化学習エージェントを用いた学習法です。
強化学習は教師なし学習の一つであり、エージェントは自律的に行動し学習規則を獲得します。
したがって、システムの設計者は環境の変化に応じて設計を施す必要がありません。
マルチエージェントシステムは、複雑はタスクを実行する大規模なシステムへの応用が期待されており、新しい分散協調システムとして注目されています。
強化学習
強化学習は学習主体であるエージェントと環境との相互作用から成ります。
まず、エージェントは環境から状態を観測します。そして、状態に応じて行動を選択します。
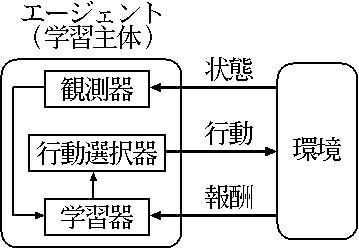
そして、行動の結果として環境から報酬を受け取ります。
エージェントはその報酬を元に、選択した行動が適切であったか否かを学習します。
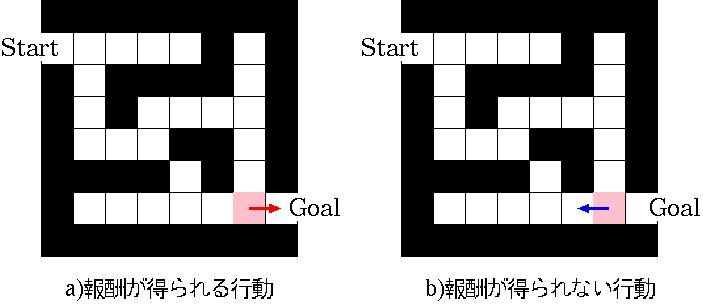
例えば、エージェントに迷路を解く学習を行わせた場合、下の図a)のようにピンク色で示した場所から右へ移動する行動はゴールへ到達するための適切な行動であり、報酬を得ることができます。したがって、エージェントはピンク色で示した場所では右へ移動したほうが良いことを学習します。一方で、図b)のように左へ移動する行動を選択した場合には報酬を得ることができず、左へ移動する行動は適切でなかったことを学習します。
追跡問題
追跡問題は、マルチエージェント環境下での協調問題として広く用いられている問題です。複数のハンターが協力して獲物を捕獲するという問題で、図のようなグリッド環境でシミュレーションを行うことが一般的です。
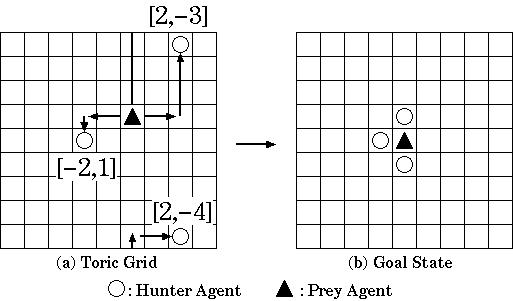
このグリッドはトーラス状で上端と下端、右端と左端がつながっています。エージェントは上下左右と停止の5つの行動中から行動を選択し、図(b)のゴール状態となった時に報酬を受け取ります。
この追跡問題では、各エージェントが同時に獲物に隣接しない限り報酬を得ることができません。したがって、エージェント間での協調が重要となってきます。マルチエージェント強化学習の分野では、各エージェントは自律的に行動・学習を行いながら、いかにして協調行動を獲得できるかについて多くの研究がなされています。