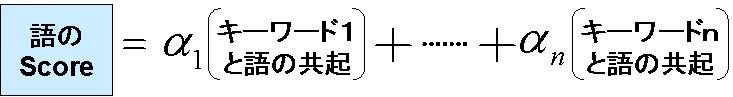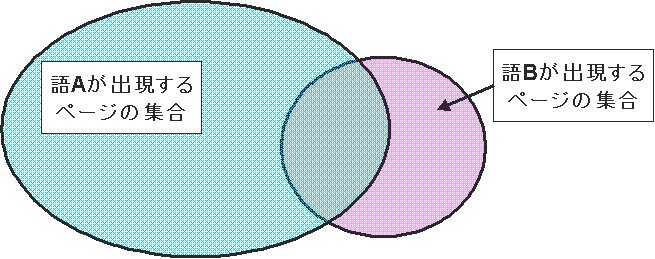
図1:語の共起性
語の共起性は以下の式で表される。これは、図1の2つの集合の重なり具合を表している。
現在、Web上の莫大な情報の中から、ユーザが必要な情報を 得る手段として検索エンジンが広く用いられている。 各検索エンジンでは、検索結果を順位付けし、 一般的に評価の高いWebページを検索結果の上位と することで効率化を図っている。 しかし、有用であるということは主観的であるため、 一般的に評価の高いページが誰にでも有用であるとは限らない。
本研究では、ユーザが入力した検索キーワードと Webページ内に含まれる語との共起性を用いて、 Webページを評価し、さらにユーザからのフィードバックを 得ることで、各ユーザの要求により適合した結果を提示する 検索方法を提案する。
多くの自然言語文書処理において用いられている 代表的な手法に tfidf(Term Frequency-Inverse Document Frequency)法 [1][2]がある。 対象とする文書中に頻繁に出現し(網羅性)、 他の文書にあまり出現しない(特定性)ような語を 重要と見なす方法である。
しかし、重要性は主に語の出現頻度で算出されるが、 Webページのように多様性の高い文書では、 出現頻度が重要性の目安とはなりにくい。 また、特定性を評価するための適切な文書数を 得るに十分なWebページ数を集めることは困難である。
Web検索の効率化を図るための代表的な手法として、 HITS(Hyperlink-Induced Topic Search)アルゴリズム[3]と 検索エンジンGoogleで利用されている PageRankアルゴリズム[4]がある。どちらも各Webページに対して、 固定的に評価値を与え、検索結果を評価値の大きい順に 提示する方法である。
しかし、有用な情報はユーザによって異なるため、 全てのユーザに対して画一的な評価による 順位付けでは、ユーザの要求を満たすことはできない。
語の共起性[5]とは、 任意の2つの語が同時に出現する 割合のことであり、 語の関連性の強さを表すもので ある。
図1:語の共起性
語の共起性は以下の式で表される。これは、図1の2つの集合の重なり具合を表している。
キーワードの各語との共起の強さを評価し、 評価の高い語を抽出することにより、 キーワードと関連性の強い語群を得ることができる。
以下が、語の評価値scoreの評価式である。 この値が大きいものはキーワードとの関連性の強い語となる。また、抽出した関連性の強い語群を用いて、 キーワードに関連性の高い語をどれほど保有しているかを 評価した値をページに付加する。
以下がページの評価値を決定する式である。 評価値の高いページは、キーワードにより 関連性の高いページである。
検索結果の中でユーザが有用であると 判断したページをシステムに伝達すること (フィードバック)により、語の共起を強化する。 ユーザが優良と判断したページをシステムに フィードバックし、優良ページ内に含まれる語と キーワードの共起を 強化していくことにより、優良ページ及び優良ページに 類似した内容のページを少ないキーワードでも 検索結果の上位とすることができる。
強化を行った共起は以下の式で表される。 強化値を増減することにより、ユーザの要求を反映する。
提案手法を評価するために実験を行った。 キーワード「apple(重み 1.0)」に対して、 以下の3つの場合について比較を行う。
- 検索エンジンGoogleでの結果
提案手法との比較を行うため- Apple Computer社のページを優良とするユーザ
事前に、apple,computer,ipod,itunesなどの語を用いて検索を行い、 Apple Computer社のページを優良としてフィードバックを行った。- りんごのページを優良とするユーザ
事前に、apple,fruit,red,freshなどの語を用いて検索を行い、 りんごのページを優良としてフィードバックを行った。
 |
 |
 |
|---|---|---|
 |
|
 |
|---|---|---|
 |
 |
 |
|---|---|---|
varieties/index.html |
products/apples/varieties.html |
以上の結果から、各ユーザの意図を反映して、 検索結果を変化させ、 各ユーザの要求に適した結果を 出力できていることを確認した。
[1] 小熊 淳一,内海 彰,「語の共起情報を用いたクラスタリング」, ,2005.6.
[2] 清水 力,相田 仁,「HTML構造における頻出パターンのマイニングによる WWWからの情報抽出」,2004.3.
[3] J.Kleinberg, 「Authoritative Sources in a Hyperlinked Environment」, 1998.
[4] Sergey Brin,Lawrence Page, 「The Anatomy of a LargeScale Hypertextual Web Search Engine」,1998
[5] 森 純一郎,松尾 豊,石塚 満,「Webからの人物に関するキーワード抽出」 ,2005.9.